tq_entry
The transaction queue entry Micro-Architecture-Specification
Block Diagram
TODO - insert the block diagram
Top level interface
| Name | Size | Direction | Description |
|---|---|---|---|
| clk | 1 bit | In | Clock signal for synchronous operation |
| rst | 1 bit | In | Reset signal for resetting the module |
| entry_id | 3 bits | In | Entry identifier for this module |
| core2cache_req | 60 bits | In | Core-to-cache request data |
| allocate_entry | 1 bit | In | Signal to allocate an entry |
| fm2cache_rd_rsp | 149 bits | In | FM-to-cache read response data |
| pipe_lu_rsp_q3 | 164 bits | In | Pipe lookup response data |
| first_fill | 1 bit | In | Signal indicating the first fill |
| cancel_core_req | 1 bit | In | Signal to cancel the core request |
| tq_entry | 162 bits | Out | TQ entry data output |
| next_tq_entry | 162 bits | Out | Next TQ entry data output |
| rd_req_hit_mb | 1 bit | Out | Signal indicating a read request hit |
| wr_req_hit_mb | 1 bit | Out | Signal indicating a write request hit |
| free_entry | 1 bit | Out | Signal indicating a free entry |
| fill_entry | 1 bit | Out | Signal indicating a fill entry |
Main components:
TQ entry Flops:
Motivation:
In the design of our cache architecture, the 'tq entry' plays a crucial role in managing the interactions between the core processor and the cache subsystem. It serves as the entry point for incoming requests, tracks the state of each request, and handles data merging and storage. To provide a comprehensive understanding of its operation, we present a detailed analysis of the flip-flops used within the 'tq entry' module. These flip-flops control various aspects of the entry's behavior, such as request indications, merge buffer management, and address tracking. By documenting and analyzing these flip-flops, we aim to shed light on the inner workings of this essential component, facilitating both comprehension and potential enhancements to our cache architecture.
Table of Flops:
| Name | Size | Description | when & how data writes | who consumes the data |
|---|---|---|---|---|
| state | 3 bits | State of the TQ Entry | State transition | |
| merge_buffer_e_modified | 4 bits | Indication of merge Buffer modification | Bit is set when data in MB is modified | |
| rd_indication | 1 bits | Read indication | Bit is set when read request is processed | |
| wr_indication | 1 bits | Write indication | Bit is set when write request is processed | |
| merge_buffer_data | 128 bits | Data stored in the merge buffer | When merge buffer data is updated | |
| cl_address | 16 bits | Cache Line Adress | When cache line address is set | |
| cl_word_offset | 2 bits | Word offset within a Cache Line | When word offset is set | |
| reg_id | 6 bits | Register identifier | When register identifier is set |
TQ entry FSM:
Motivation:
In the heart of our cache architecture lies the TQ (Transaction Queue) entry Finite State Machine (FSM). This FSM orchestrates the intricate dance between core processor requests, cache hits and misses, data merging, and state transitions within each TQ entry. Understanding the TQ entry FSM is paramount for comprehending the inner workings of our cache system. This section provides a comprehensive overview of the TQ entry FSM, shedding light on the transitions, conditions, and actions that shape the behavior of each entry.
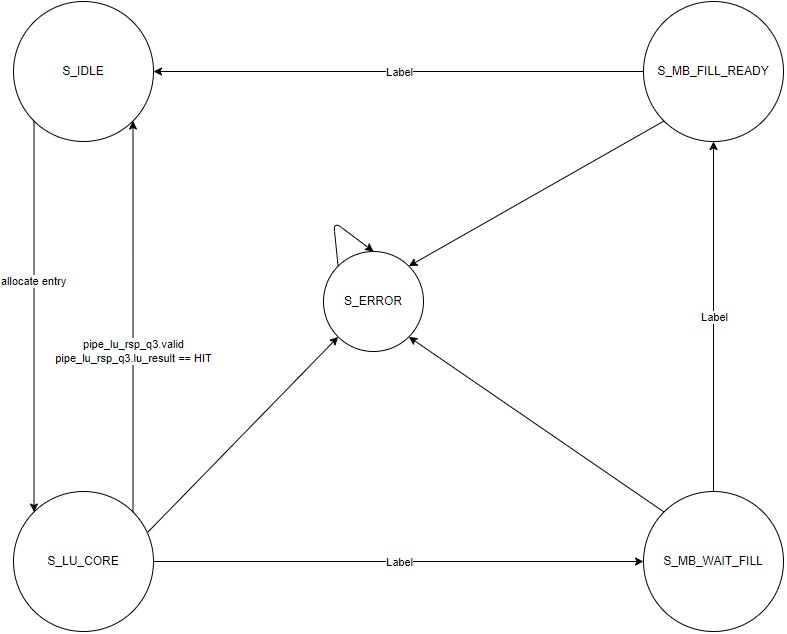
Table of FSM states:
| Name | Possible Next State | Description |
|---|---|---|
| S_IDLE | S_LU_CORE | Waiting for a core request to allocate the entry |
| S_LU_CORE | S_IDLE / S_MB_WAIT_FILL | Core requests are being processed, and interactions with LU pipe may occur |
| S_MB_WAIT_FILL | S_MB_FILL_READY | The module is waiting for a cache fill response. |
| S_MB_FILL_READY | S_IDLE | The module is ready to send a cache fill response to the LU pipe |
| S_ERROR | Indicates an unexpected or erroneous situation |
Diagram of the TQ entry FSM:
Typical FSM flow:
Write Hit:
S_IDLE -> S_LU_CORE -> S_IDLE
New write request from the core
TQ entry is allocated in parallel to the pipe lookup
TQ entry merge buffer is updated speculatively with the new request data
Lookup response is received as a hit - the TQ data is discarded. Entry returns to S_IDLE
(There is a case of B2B writes where the TQ state will not return to S_IDLE until the "last write" to the same CL responds from lookup. See Merge Buffer Behavior for more details.)
Write Miss:
SIDLE -> S_LU_CORE->S_MB_WAIT_FILL -> S_MB_FILL_READY -> S IDLE
- New write request from the core
- TQ entry is allocated in parallel to the pipe lookup
- TQ entry merge buffer is updated speculatively with the new request data.
- Lookup response is received as miss - moving to the MB_WAIT_FILL state.
- Far memory response is received, Merge buffer updates the write with the fill data,moving to the MB_FILL_READY state.
- The TQ entry wins the arbitration to send the "Fill" to the lookup pipe -> movingto the S_IDLE state.
Note: We have a guaranty that the fill lookup will always win cache allocation. Meaning there is no "miss" for a fill request. this allows us to move to the S_IDLE state without waiting for the lookup response.
Read Hit:
SIDLE -> S_LU_CORE->S IDLE
- New read request from the core
- TQ entry is allocated in parallel to the pipe lookup
- TQ entry merge buffer is updated speculatively with the new request data
- Lookup response is received as hit - the TQ data is discarded. Entry returns to S_IDLE
Read Miss:
SIDLE -> S_LU_CORE->S_MB_WAIT_FILL -> S_MB_FILL_READY -> S IDLE
- New read request from the core
- TQ entry is allocated in parallel to the pipe lookup
- There is no Data updated to the TQ entry merge buffer (this is a read request)
- Lookup response is received as miss - moving to the MB_WAIT_FILL state.
- Far memory response is received, Merge buffer updates the write with the fill data, moving to the MB_FILL_READY state.
- The TQ entry wins the arbitration to send the "Fill" to the lookup pipe -> moving to the S_IDLE state.
Note: We have a guaranty that the fill lookup will always win cache allocation.
Meaning there is no "miss" for a fill request.
this allows us to move to the S_IDLE state without waiting for the lookup response.
TQ entry merge_buffer:
Motivation:
The merge_buffer is a buffer in our TQ that will store partial data during the time we are waiting for the Cache Line Data to be filled by the Far Memory. Every entry in the TQ is linked to a Merge Buffer entry then we need to take care that every request to the same Cache-Line will never allocate a new entry if there already is an entry in the TQ for that specific Cache-Line.
Examples:
Write after Write
If the first write hits:
- The merge buffer will be discarded due to all the data is already updates in the cache.
- The TQ entry will not go back to the S_IDLE state as long there are write request to that same CL in the lookup Pipe.
This is achieved by having a "req_match_in_pipe" indication in the lookup response struct.
If the first write misses:
- The merge buffer will be merge with the second write data.
- The first write will respond with a "miss" which will cause the TQ entry to go to the MB_WAIT_FILL state.
- Any new write to that same CL will be merged with the merge buffer data.
- Once the Far memory response is received, the merge buffer will be updated with the fill data.
- The TQ entry will win the arbitration to send the "Fill" to the lookup pipe -> moving to the S_IDLE state.
Read after Write
- If the first write request hits:
- The merge buffer will be discarded due to all the data is already updates in the cache.
- The TQ entry will not go back to the S_IDLE state as long there are request to that same CL in the lookup Pipe.
This is achieved by having a "req_match_in_pipe" indication in the lookup response struct.
- If the first write request hits: