intro
Making a CPU is tough work. It needs big teams to build a powerful and modern CPU, considering things like power usage, size, and speed. But all modern CPUs go through the same steps, which we'll explain here: fetching data (IF), decoding it, doing the actual work (EXE), getting data from memory (MEM-ACS), saving results (WB), and a controller that manages everything.
The stages we mentioned don't depend on the type of ISA we pick.
There are three main ways to make a CPU. The first one is the single cycle way, the second is the multi-cycle way, and the third is the pipeline way. The first two are not so common; we mainly use them to explain how a CPU works more simply. They can be a good way to start building a CPU if you're new to it. The third one is the most popular and used in all modern processors. Now, let's talk a bit about each of these methods.
CPU design approaches:
Single Cycle
A single-cycle processor executes one instruction in a single clock cycle. It fetches, decodes, performs the operation, and writes back the result in a single step. This approach is simple to understand but not very efficient mostly because the data-path is very long and the clock cycle is determined by the longest instruction causing to low frequency, low throughput and high latency.
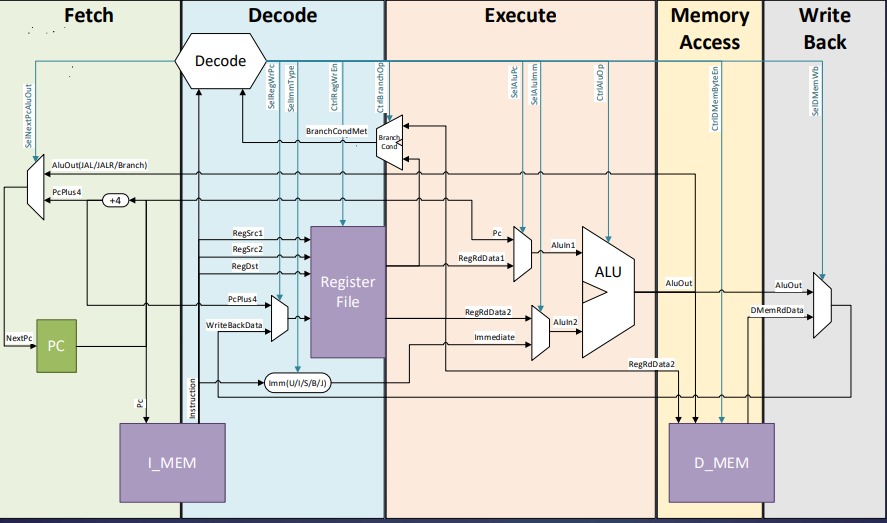
- You may refer to the following figure to see how a single cycle processor works. To see the code for this processor, you can go to the
sourcesfolder in thesc_corefolder. sc_corebased on the following diagram:
Multi Cycle
A multi-cycle processor breaks instruction execution into multiple clock cycles, with each cycle handling a specific task (e.g., fetch, decode, execute). This approach is more complex but allows for more efficient use of hardware resources because the data-path is shorter and the clock cycle is determined by the longest stage. This approach is more efficient than the single cycle approach but still not very efficient because the clock cycle is determined by the longest instruction.
Pipeline
A pipelined processor is a complex design that enhances CPU efficiency by allowing multiple instructions to be processed concurrently, in a staged manner. Here's a detailed explanation of how it works:
Pipeline Stages: The CPU is divided into several stages, typically five: Fetch, Decode, Execute, Memory, and Write-Back. Each stage performs a specific part of the instruction processing.
Instruction Fetch (IF): The first stage fetches the next instruction from memory. While one instruction is being fetched, the previous one can move on to the decode stage.
Instruction Decode (ID): In this stage, the CPU decodes the fetched instruction to determine what operation it represents and identifies the required registers. Meanwhile, the previous instruction moves to the execute stage, and the next instruction is fetched.
Execution (EXE): This stage performs the actual operation specified by the instruction. Simultaneously, the previous instruction proceeds to the memory access stage, the one before that goes to the write-back stage, and the next instruction enters the decode stage. Memory Access (MEM):
If the instruction involves memory operations, like reading or writing to memory, this stage handles them. At the same time, the previous instruction moves to the write-back stage, and the one before it advances to the memory stage.
Write-Back (WB): In this stage, the CPU writes the results of the executed instruction back to the appropriate registers. The previous instruction may retire (complete its execution), and the next instruction enters the decode stage.
Stall and Bypass: To handle data dependencies or hazards (situations where an instruction depends on the result of a previous instruction), the pipeline can "stall" or "bypass" data from previous stages to ensure proper sequencing. Continuous Flow:
The key advantage of pipelining is that each stage operates concurrently, so while one instruction is in the execute stage, another is in the decode stage, and a third is being fetched. This overlapping of tasks leads to better CPU throughput and overall performance. Hazards:
Although pipelining enhances performance, it can also introduce issues like data hazards (when one instruction relies on data produced by a previous instruction) and control hazards (when a branch instruction changes the program flow). These must be managed through techniques like forwarding, speculative execution, or stalling. In a well-designed pipeline, the CPU can process several instructions at the same time, significantly increasing its overall performance and throughput. However, handling hazards and ensuring instructions are processed in the correct order are key challenges in pipelined processor design.
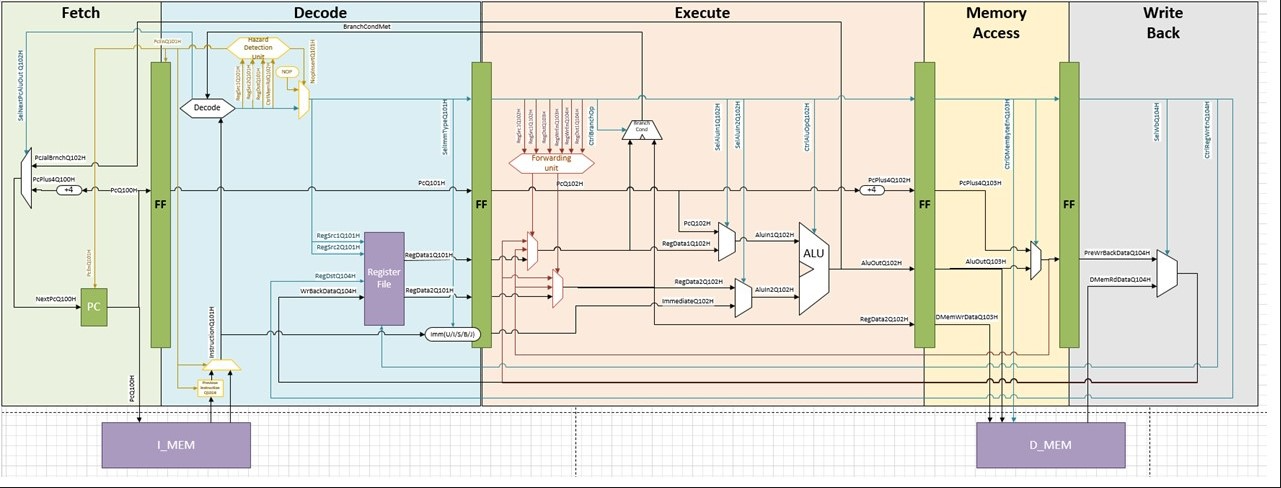
- You may refer to the following figure to see how a single cycle processor works. To see the code for this processor, you can go to the
sourcesfolder in themini_corefolder. 5_stage_corebased on the following diagram:
for additional information about the pipeline and how to build a CPU, you can go to: orig_docs -> CPU_Arch folder in the GitHub-Wiki repository