mem_wrap
Introduction
The Memory Wrapper wraps together all the types of memories in the system like Instruction Memory, Data Memory, VGA Memory and more if existed.
The Memory wrapper plays a crucial role in MMIO by switching between different memory areas.
Its goal is to provide an interface between the core and the memory.
The Figure below illustrates this interface in HAS_RVC_ASAP project 1: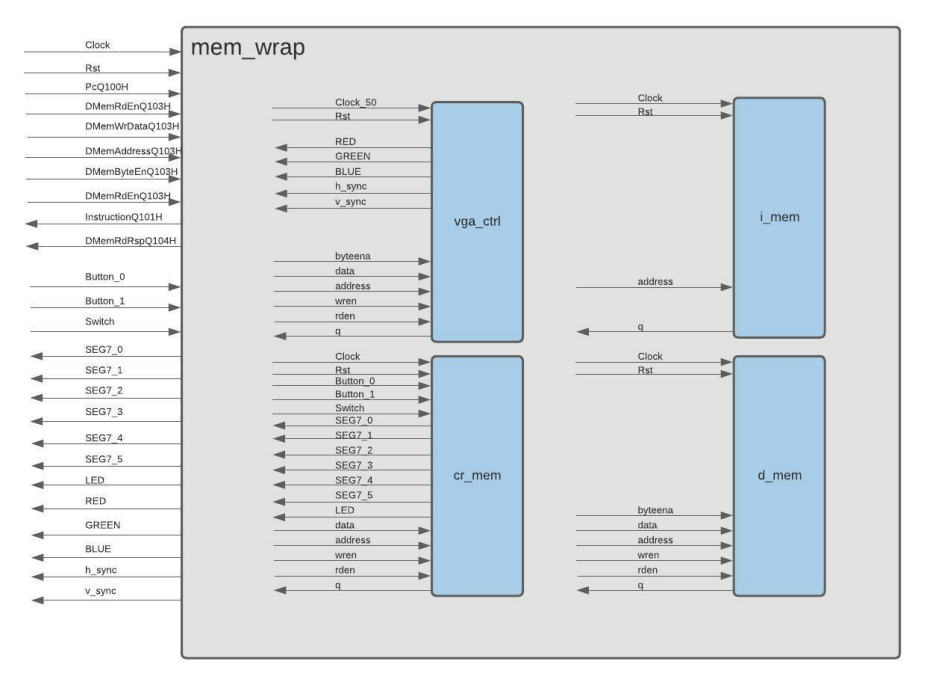
HW/SW Memory granularity
- On the most important issues when designing the memory wrapper is the granularity of the memory.
- The granularity of the memory is the number of bytes that the memory can read/write in one cycle.
- The granularity of the Instruction Memory in our cores is 1 byte. The granularity of the Data Memory is 4 bytes.
- The granularity of the Instruction and Data Memory as defined by the compiler is 1 bytes. This means that the we have to compensate for the difference between the granularity of Data Memory seen by the compiler and the core.
- Before we start to explain how we compensate for the difference, we have to remember the following:
- The compiler sees the memory as a byte array.
- The core sees the data memory as a word array.
- The compiler stores/loads words to addresses that only can be divided by 4. For example storing to address 0x1000 is legal, but storing to address 0x1001 is illegal.
- The compiler stores/loads half words to addresses that can be divided by 2.
- The compiler stores/loads bytes to any address.
note: when you try to run the core from your own assembly code, you also have to follow the above rules.
Lets demonstrate the difference between the compiler and the core with an example:
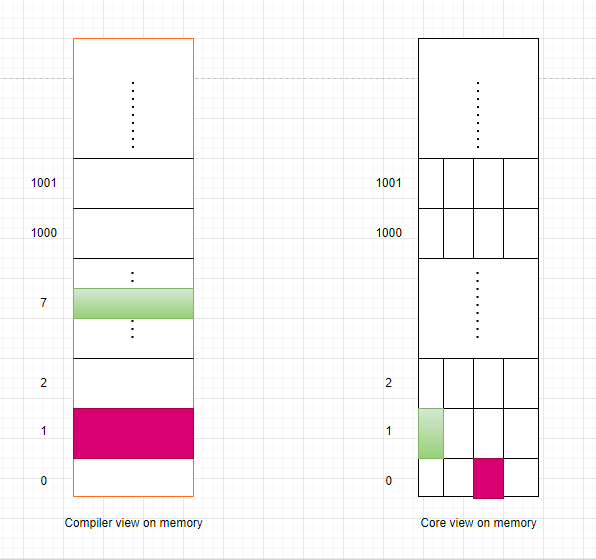
As we can see from the above figure, all the addresses from 0-3 in the compiler view are mapped to address 0 in the core view. The same goes for addresses 4-7, 8-11 and so on.
Thats why the address supplied to the core do not include the 2 lsb bits of the address.
For example: if the compiler wants to store/load something to/fromaddress[31:0]we supply theaddress[31:2]to the core.When we write a word to address 0-3 in the compiler view, the core will write the word to address 0. When we write a word to address 4-7 in the compiler view, the core will write the word to address 1 and so on. When we write half a byte to address 0-1 in the compiler view, the core will write the half word to address 0 at bits [15:0]. When we write half a byte to address 2-3 in the compiler view, the core will still write the half word to address 0 and so on but into bits [31:15]
To fix that we look at the 2 lsb of the address and decide how to handle the store/load.
Store into data memory of the core
always_comb begin
ShiftDMemWrDataQ103H = (DMemAddressQ103H[1:0] == 2'b01 ) ? { DMemWrDataQ103H[23:0],8'b0 } :
(DMemAddressQ103H[1:0] == 2'b10 ) ? { DMemWrDataQ103H[15:0],16'b0 } :
(DMemAddressQ103H[1:0] == 2'b11 ) ? { DMemWrDataQ103H[7:0] ,24'b0 } :
DMemWrDataQ103H;
ShiftDMemByteEnQ103H = (DMemAddressQ103H[1:0] == 2'b01 ) ? { DMemByteEnQ103H[2:0],1'b0 } :
(DMemAddressQ103H[1:0] == 2'b10 ) ? { DMemByteEnQ103H[1:0],2'b0 } :
(DMemAddressQ103H[1:0] == 2'b11 ) ? { DMemByteEnQ103H[0] ,3'b0 } :
DMemByteEnQ103H;
end
Read from the memory of the core
assign PreDMemRdDataQ104H = (DMemAddressQ104H[1:0] == 2'b01) ? { 8'b0,PreShiftDMemRdDataQ104H[31:8] } :
(DMemAddressQ104H[1:0] == 2'b10) ? {16'b0,PreShiftDMemRdDataQ104H[31:16]} :
(DMemAddressQ104H[1:0] == 2'b11) ? {24'b0,PreShiftDMemRdDataQ104H[31:24]} :
PreShiftDMemRdDataQ104H ;
- for example: if the compiler wants to store byte to address 3 in the memory as seen from the compiler view, than the data will be stored in address 0 of the core in bits 31:24. When we loads the data we do the opposite.
- Lets take another example:
- lets assume we want to store byte
0x10in address8'b00000111, We will also assume for simplicity that the address range is 8 bits instead of 32. This scenario is shown in the above figure as green color, meaning that we write into 4-th byte of address1. - The address that generated in the compiler and red by the core is :
8'00000111because the compiler do not care about the granularity of the core. - The address that passed to the Data Memory from the wrapper is
6'000001. (We remind you the 2 removed lsb bits). - The data signal
ShiftDMemWrDataQ103His0x10000000and written into address6'b000001meaning that we write to the green rectangular as suppose to be.
- lets assume we want to store byte
- The best way to understand this is to perform a short simulation on your own paper and see how the data is stored and loaded when storing and than loading bytes, half words and words.
- The figure is taken from HAS_RVC_ASAP project. You can find the original file at
/orig_doc/CPU_Arch/reference_rvc_asap/ HAS_RVC_ASAP.pdf↩